
Einführung
In den letzten Jahren wurden die Rechenleistung sowie die Komplexität der Algorithmen immer höher. Dennoch war die Nutzung von menschlichen Erkenntnissen in jedem unserer Projekte von STATWORX ein wichtiger Bestandteil bei der erfolgreichen Durchführung eines Projektes. In diesem Artikel soll auf das Einbeziehen von Wissen über Monotoniebedingungen in ein Modell eingegangen werden.
Zunächst soll dazu die Monotoniebedingung definiert werden.
Mathematisch betrachetet bedeutet eine monoton steigende Funktion, dass bei beliebigen  bei denen
bei denen  , dann gilt:
, dann gilt:
![\[f(x_1) \le f(x_2)\]](https://wordpress-112839-321398.cloudwaysapps.com/wp-content/ql-cache/quicklatex.com-88f0eec7aedfd18827617c50ea02327c_l3.png "Rendered by QuickLaTeX.com")
Gilt hingegen, dass und  , wird von einer monoton fallenden Funktion gesprochen.
, wird von einer monoton fallenden Funktion gesprochen.
Doch wie lässt sich diese Eigenschaft auf ein konkretes Business Problem anwenden und was bedeutet dies für unser Modell?
Nehmen wir zum Beispiel die Vorhersage des Preises einer gebrauchten Maschine.
Versucht man diesen Preis durch ein mathematisches Modell vorherzusagen, ist der Preis der gebrauchten Maschine das Ergebnis einer Funktion  , die von mehreren Variablen abhängt.
, die von mehreren Variablen abhängt.
In unserem Beispiel können das der Neupreis der Maschine, der Einsatzort und die Laufzeit der Maschine sein. Aus betriebswirtschaftlicher Sicht ist dabei eine monoton fallende Funktion zwischen dem Preis und der Laufzeit zu erwarten. Bei der Verwendung nicht linearer mathematischer Modelle kann es jedoch vorkommen, dass das Modell zwar bei großen Differenzen in der Laufzeit einen negativen Zusammenhang zwischen Laufzeit und Preis einer Maschine vorhersagt, es jedoch bestimmte Regionen gibt, in denen das Modell einen positiven Zusammenhang zwischen Preis und Laufzeit ermittelt.
In einem Projekt wäre das aus zwei Gründen problematisch.
- Ein Argument ist die Akzeptanz des Modells bei Fachexperten, die die Vorhersagen nutzen möchten. Diese werden einem Modell, das nicht monoton ist, wenig vertrauen.
- Der andere Grund ist, dass Overfitting vermieden werden kann und die Performance auf dem Test-Set somit verbessert wird. Dies liegt daran, dass zum Beispiel bei einem tatsächlich monoton fallenden Zusammenhang ein steigender Zusammenhang durch einige wenige Fälle verursacht worden ist, bei denen andere, nicht in dem Modell aufgenommene Variablen, das Ergebnis verzerrt haben.
Simulation
Für ein erstes Beispiel werden simulierte Daten genutzt. Dazu wurde eine Zielvariable  in Abhängigkeit von den Variablen
in Abhängigkeit von den Variablen  in der folgenden Form simuliert:
in der folgenden Form simuliert:
![\[y = (x_1^3 + x_1^2 - x_1) / 1000 + 2x_2 - 0.5x_3 + Rauschen\]](https://wordpress-112839-321398.cloudwaysapps.com/wp-content/ql-cache/quicklatex.com-2eeac00c5b9764decee51ba2245b58b2_l3.png "Rendered by QuickLaTeX.com")
Dabei sind  sowie
sowie  jeweils normalverteilte Zufallsvariablen. Insgesamt wurden 150 Fälle simuliert.
jeweils normalverteilte Zufallsvariablen. Insgesamt wurden 150 Fälle simuliert.
Im nächsten Schritt werden zwei Modelle mit dem R-Package GBM gelernt, die die Zusammenhänge der Funktion schätzen sollen. Dabei wird ein Modell ohne Beschränkungen und eines mit Beschränkungen gelernt.
Hier ein Beispiel, bei dem für die erste Variable eine monoton steigende Funktion angenommen wird:
# Training eines Boosted Modells ohne Monotoniebeschränkungen
model_constrained <- gbm(formula, data = df, n.trees = n_trees,
distribution = "gaussian")
# Training eines Boosted Modells mit Monotoniebeschränkungen
model_constrained <- gbm(formula, data = df, n.trees = n_trees,
distribution = "gaussian",
# Beschränkung der ersten Variable
var.monotone = c(1,0,0)) Die Implementierung von Monotoniebedingungen ist teilweise auch in anderen Packages vorhanden. So können Monotoniebedingungen bei Random Forests in R mit dem Package Rborist implementiert werden. In Python ist eine Implementierung unter anderem für XGBoost vorhanden.
Nehmen wir für unser Modell an, dass den Fachexperten bekannt ist, dass der Zusammenhang zwischen  und monoton steigend ist, was der simulierten Funktion entspricht. In der Funktion gbm() lässt sich das einfach über das Funktionsargument var.monotone implementieren. Dem Funktionsargument muss ein Vektor übergeben werden, der für jede Einflussvariable angibt, ob ein positiver (1), negativer (-1) oder unspezifizierter (0) Zusammenhang vorliegt.
und monoton steigend ist, was der simulierten Funktion entspricht. In der Funktion gbm() lässt sich das einfach über das Funktionsargument var.monotone implementieren. Dem Funktionsargument muss ein Vektor übergeben werden, der für jede Einflussvariable angibt, ob ein positiver (1), negativer (-1) oder unspezifizierter (0) Zusammenhang vorliegt.
Um den Einfluss einer Variablen zu erkennen, wird hier der Partial Dependence Plot genutzt. Dieser zeigt den Einfluss einer Variablen an, wenn alle anderen Variablen als fest angenommen werden.
In der folgenden Grafik ist dabei der Einfluss von auf die Zielvariable dargestellt. Dabei ist zu erkennen, dass es in dem Modell ohne Beschränkungen Bereiche gibt, in denen ein negativer Zusammenhang vorliegt, was in dem Modell mit Beschränkungen nicht der Fall ist.
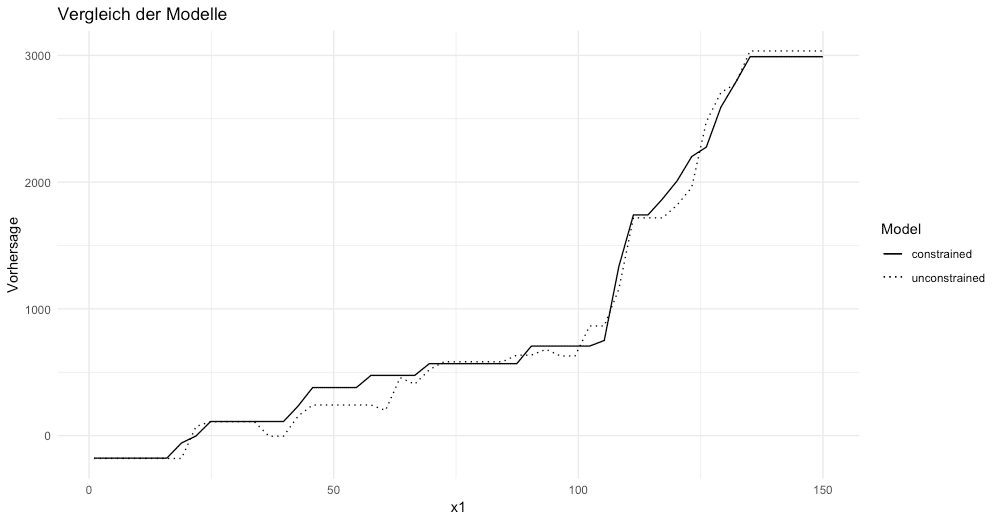
Schauen wir uns im nächsten Schritt den MAE an, erkennen wir, dass auch dieser beim Modell mit Constraints von 749,3 auf 744,1 sinkt. Das Modell ohne Constraints hat sich also zu stark den Trainingsdaten angepasst (Overfitting), wodurch die Performance auf den Testdaten schlechter war, als beim Modell ohne Constraints.
Praxisbeispiel
Jetzt können wir die Ergebnisse auf ein konkretes Problem anwenden. Nehmen wir dazu an, dass eine Immobilienfirma den Wert von neuen Immobilien schneller ermitteln möchte, wozu ein Machine Learning Modell entworfen werden soll. In Gesprächen mit Fachexperten wurde ermittelt, dass ein positiver Zusammenhang zwischen der Größe des Grundstücks und dem Preis der Immobilie vorliegt.
Um das Modell zu berechnen wird ein Datensatz zur Verfügung gestellt. Die zugehörigen Daten können hier heruntergeladen werden.
Der Datensatz enthält insgesamt 81 Spalten, wovon für diesen Artikel jedoch zur Übersichtlichkeit nur wenige genutzt werden. In unserem Modell wird als Zielvariable der Preis gewählt und als Einflussvariablen werden die Anzahl an Square Feet des Grundstücks (LotArea), der Zustand der Garage (GarageCond), der Typ des Hauses (HouseStyle) sowie die Qualität des Materials (OverallQual) genutzt.
Hier ein kurzer Ausschnitt aus den Daten:
| price | LotArea | HouseStyle | GarageCond | OverallQual |
|---|---|---|---|---|
| 208500 | 8450 | 2Story | TA | 7 |
| 181500 | 9600 | 1Story | TA | 6 |
| 223500 | 11250 | 2Story | TA | 7 |
| 140000 | 9550 | 2Story | TA | 7 |
| 250000 | 14260 | 2Story | TA | 8 |
| 143000 | 14115 | 1.5Fin | TA | 5 |
Nach der Auswahl der Variablen und dem Bilden einer Formel, wird jeweils ein Modell ohne Beschränkungen bezüglich der Monotonie und eines mit einer Beschränkung der Square Feets gerechnet. Bildet man daraufhin einen Partial Dependence Plot, erkennt man in dem Modell ohne Beschränkungen im Bereich von circa 12.000 – 18.000 Square Feet, dass bei steigender Quadratmeteranzahl der Preis sinkt. In dem Modell mit Beschränkungen ist dies nicht der Fall, was der menschlichen Intuition entsprechen würde.
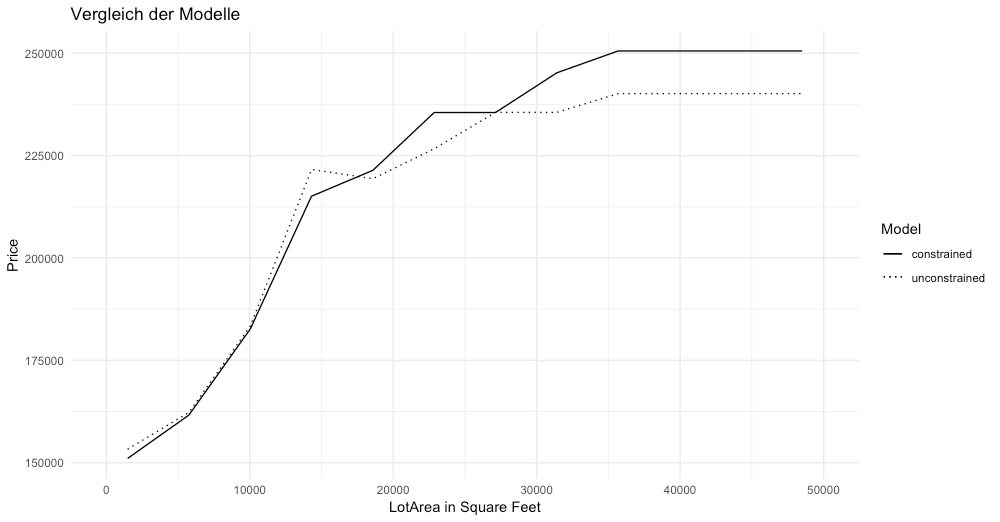
Vergleicht man weiterhin den Mean Average Error, erkennt man, dass das Hinzufügen von Beschränkungen in unserem Fall sogar zu einer leichten Verbesserung der Vorhersagegüte von einem MAE von 30875$ auf 30085$ geführt hat. In diesem Fall konnte durch das Hinzufügen von Fachkenntnissen das Modellergebnis also verbessert werden.
Wie eben gezeigt, kann das manuelle Einfügen von menschlicher Fachkenntnis sowohl die Interpretierbarkeit als auch die Vorhersagegüte verbessern. Es lohnt sich daher als Data Scientist immer, in ständigem Austausch mit der Fachabteilung Modelle zu entwickeln.
Über den Autor
ABOUT US
STATWORX
is a consulting company for data science, statistics, machine learning and artificial intelligence located in Frankfurt, Zurich and Vienna. Sign up for our NEWSLETTER and receive reads and treats from the world of data science and AI. If you have questions or suggestions, please write us an e-mail addressed to blog(at)statworx.com.