
Wie jedes Jahr in der Vorweihnachtszeit, dreht sich auch diesen Dezember bei den STATWORX-Mitarbeiter*innen alles um Weihnachtsmusik, Geschenke und Glühwein. Korrekterweise muss ich aber sagen, dass nicht alle Kolleg*innen so verrückt nach Weihnachten sind wie ich oder meine Kollegin Anne-Marie. Aber darf man sie gleich in die Grinch-Schubladen stecken, nur weil sie keine kompletten Weihnachtsfreaks sind? Um unsere Kolleg*innen in puncto Weihnachtsverrücktheit besser einschätzen zu können, hatte Anne-Marie die Idee die Einstellung zu einigen Aspekten, die mit Weihnachten einhergehen, abzufragen, um sie anhand dieser Ergebnisse ihrem Weihnachtstyp zuzuordnen.
Vor allem bei der Einteilung dieser Weihnachtstypen stießen wir jedoch auf einige Hürden. Wir wollten gerne direkt nach der Beantwortung aller Fragen den jeweiligen Typ angezeigt haben, wollten aber auch ein möglichst zutreffendes Ergebnis erhalten. Wir hatten die Wahl zwischen der Einteilung anhand eines Summenscores oder der Verwendung einer Clusteranalyse zur Gruppierung der Befragten. Letztendlich haben wir uns für ersteres entschieden. Aber so ganz möchte ich mich noch nicht mit dem Summenscore zufriedengeben. Daher nutze ich diesen Blogartikel, um zu erläutern, warum hier unterschiedliche Ergebnisse zu vermuten sind und möchte auch praktisch prüfen, ob sich die Ergebnisse einer Clusteranalyse grundlegend von unserer Einteilung anhand der Summenscores unterscheiden.
Fragen über Fragen
Wie kam die Weihnachtsumfrage eigentlich zustande? Nach der Entscheidung, dass wir die Umfrage erstellen möchten, entwickelten wir Fragen zu Themen wie der Nutzung von Adventskalendern, dem Essen an Heiligabend oder der Notwendigkeit von Weihnachtsdekoration. Anne-Marie, die im Marketing arbeitet und vor Kreativität strotz, ließ sich witzige Antworten auf unsere Fragen einfallen. Meine Befürchtung war aber, dass die wissenschaftliche Ernsthaftigkeit der Umfrage verloren gehen könnte und nahm ihr damit den ganzen Spaß.
Ich konnte etwas damit besänftigt werden, dass wir bei jeder Frage noch eine Kategorie hinzufügten, bei der angegeben werden kann, dass keine der Antworten zutrifft. Die Antwortkategorien sind außerdem so gestaltet, dass es neben der neutralen Kategorie jeweils vier Antwortkategorien gibt. Diese sind so formuliert, dass sie eine ordinale Struktur aufweisen, eine Kategorie also den größten Weihnachtsfan kennzeichnet und die Ausprägungen dann immer schwächer in Richtung Grinch werden. Bei der Durchführung der Umfrage werden die Kategorien randomisiert abgefragt, damit die ordinale Struktur nicht gleich ersichtlich ist.
Vom Summenscore zum Weihnachttyp
Im nächsten Schritt mussten wir anhand dieser Fragen bzw. deren Beantwortung noch die zugehörigen Weihnachtstypen identifizieren. Doch das war gar nicht so einfach, wie wir zunächst dachten. Anne-Marie wünschte sich, dass die Teilnehmenden der Umfrage gleich im Anschluss an die Beantwortung ein Ergebnis und damit Ihren Weihnachtstyp angezeigt bekämen. Ich fragte mich daher, wie sich dies zum einen einfach umsetzten lässt, und zum anderen, wie das Ergebnis den wahren Weihnachtstyp möglichst genau widerspiegeln könnte.
Die erste Idee war es einen Summenscore über die Antworten, die ja eine ordinale Struktur haben und damit numerischen Werten zugeordnet werden können, zu bilden. Dieser lässt sich dann in gleich große Bereiche aufteilen, die einzelnen Typen zugeordnet werden können. Ich konnte mein Statistik-Herz noch nicht vollständig damit zufriedenstellen, etwas so Wichtiges wie den Weihnachtstyp aus einer einfachen Addition der Werte zu bestimmen. Ich überlegte also weiter und dachte daran, eine Clusteranalyse zu berechnen, um Gruppen von Befragten mit ähnlichem Antwortverhalten zu identifizieren und ihnen dann anhand dieses Antwortmusters einen Typ zuzuweisen. Eine andere Idee war es, eine Diskriminanzanalyse mit Hilfe der ersten Antworten-Sets zu berechnen und anhand der Ergebnisse die Zuteilung der Weihnachtstypen vorzunehmen. Letztendlich habe ich mich dagegen entschieden, da es sich bei dieser Umfrage um ein weihnachtlich-spaßiges Tool handelt und nicht um eine wissenschaftliche Studie.
Da sich diese dritte Idee am einfachsten umsetzen ließ, haben wir uns zunächst dafür entschieden, einen Gesamtscore über alle Antworten zu ermitteln und diesen in vier Bereich aufzuteilen, die die Weihnachtstypen widerspiegeln. Wurde die Antwort „Keine der Optionen trifft auf mich zu“ oder generell keine Antwort gegeben, so wurde ein neutraler Wert hinzugefügt. Wir überlegten uns die folgenden Weihnachtstypen:
- Der Weihnachtsfreak
- Die kleine Weihnachtselfe
- Cool wie 1 Eisbär
- Der Grinch
Kleine Elfen oder cool as ice?
Aber schauen wir uns doch zunächst an, welche Einteilung sich anhand des Summenscores ergeben hat. Insgesamt haben wir 48 Befragte bei unserer kleinen Weihnachtsumfrage. Zugegeben, dies ist eine recht geringe Anzahl für die meisten statistischen Verfahren, aber wir möchten bei STATWORX auch immer wieder zeigen, wie Verfahren mit realistischen Daten anzuwenden sind und wie sich diese verhalten.
Mehr als die Hälfte unserer Befragten fällt in die Kategorie „Cool wie 1 Eisbär“, was eher eine neutrale Position gegenüber Weihnachten ausdrückt. Auch wenn eine befragte Person immer die Kategorie „Keine der Optionen trifft auf mich zu“ wählt, fällt sie theoretisch in diese Kategorie – dieser Fall kam bei der Umfrage nicht vor.
Anne-Marie und ich hätten uns natürlich gewünscht, dass alle unsere Leidenschaft teilen und sich ausschließlich Weihnachtsfreaks und -elfen zeigen. Immerhin etwa ein Drittel der Befragten entpuppt sich nach unserer Einteilung als kleine Weihnachtselfe. Es fällt nicht schwer zu erkennen, dass es keinen einzigen Weihnachtsfreak unter unseren Kolleg*innen und Freund*innen gibt.
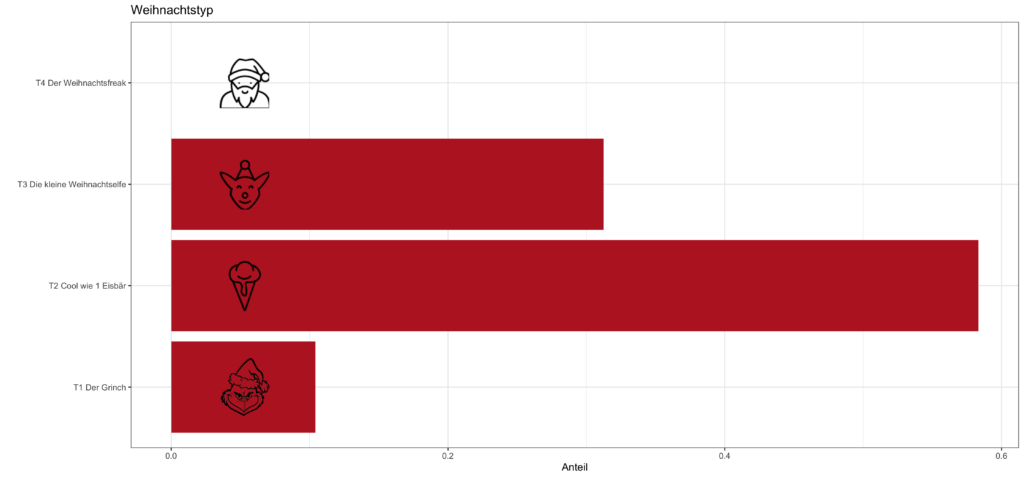
Zuerst befürchtete ich, wir hätten die Bestimmung des Typs falsch implementiert, da niemand der Kategorie „Weihnachtsfreak“ zugeordnet wurde. Die Implementierung lief fehlerfrei. Das machte mir aber bewusst, dass wohl wirklich keine Weihnachtsfreaks teilgenommen haben. (Anne-Marie und ich haben nicht mitgemacht).
Mein Missmut gegenüber dem Summenscore wuchs also zunehmend. Es wird zwar der theoretisch mögliche Wertebereich beachtet und zur Einteilung der Klassen verwendet, im Vorhinein kann jedoch noch nicht gesagt werden, welche Werte tatsächlich auftreten. Hätten wir den theoretischen Bereich also nicht einfach in vier gleichgroße Teile geteilt, sondern den Bereich für „Weihnachtsfreaks“ etwas vergrößert, dann wären auch einige Befragte in diese Kategorie gefallen.
Das Ziel der Typbestimmung ist es, den wahren Typ der Personen herauszufinden. Es ist zum einen möglich, dass wir die Einteilung falsch vorgenommen haben. Es kann aber auch sein, dass keine „Weihnachtsfreaks“ an der Umfrage teilgenommen haben bzw. dass es generell keine gibt. Vor allem mit einer kleinen Stichprobe ist es schwer herauszufinden, warum es hier keine „Weihnachtsfreaks“ gibt.
Wie sich der Weihnachtstyp auch anders bestimmen lässt
Welche Vorteile hat eine Clusteranalyse gegenüber dem Summenscore? Der Summenscore fasst die Antworten aller Fragen zusammen. Wird bei einer Frage ein niedrigerer Wert gewählt, wirkt sich das auf den gesamten Score aus, auch wenn ansonsten hohe Werte gegeben werden. Die Clusteranalyse erlaubt eine etwas komplexere Untersuchung, da ähnliche Einheiten zusammengefasst werden und nicht nur solche, die ausschließlich hohe bzw. niedrige Werte bei allen Fragen angeben.
Es ist denkbar, dass eine Einteilung in vier Kategorien, die sich nur durch die Intensität der gesamten Weihnachtsausprägung unterscheidet, nicht den eigentlichen Ausprägungen der Befragten entspricht, sondern dass der Weihnachtstyp durch einzelne Aspekten definiert wird. Einige Befragte könnten einen geringen Wert auf die vorweihnachtliche Stimmung legen, jedoch einen großen Anspruch an Geschenke haben. Andere könnte es besonders wichtig sein, an Weihnachten Zeit mit der Familie zu verbringen und gut zu Essen, jedoch könnten sie einen geringen Fokus auf Deko oder Adventskalender legen.
Diese beiden beispielhaften Gruppen würden dann durch hohe Werte bei einem Aspekt und niedrige Werte bei einem anderen Aspekt als neutral gewertet, was auch die hohe Anzahl an „Cool wie 1 Eisbär“-Weihnachtsfans erklärt. Die Clusteranalyse nimmt jedoch eine detaillierte Unterscheidung vor.
Zwei Varianten der Clusteranalyse
Grundlegend gibt es durch verschiedene Arten zur Distanzberechnung, Anzahl an verwendeten Clustern und Algorithmen eine umfangreiche Menge an Möglichkeiten, die Clusteranalyse durchzuführen. Als ein Verfahren des unsupervised learnings besteht außerdem nicht die Möglichkeit, die Modellgüte mit den üblichen Kriterien zu prüfen. Ich beschränke mich hier auf die grundlegendsten Modelle, die sicherlich noch verbessert werden können. Es ist weder der Zweck des Artikels, die Methodik von Clusteranalysen zu erläutern, noch aufzuzeigen, wie sich die Modelle noch verbessern lassen. Vielmehr soll die grundlegende Clusterlösung mit der Typbestimmung durch den Summenscore verglichen werden.
Die Antwortkategorien wurden so formuliert, dass sie eine ordinale Struktur aufweisen. Im weitesten Sinne lassen sich den Kategorien also metrische Werte geben und die Ähnlichkeit der Beobachtungen mittels euklidischer Distanz berechnen. Ich bin normalerweise sehr vorsichtig damit, ordinale Daten mit Verfahren zu behandeln, die eigentlich für metrische Daten gedacht sind. Da ich euklidischer Distanz jedoch sehr häufig bei der Clusteranalyse Anwendung finde, möchte ich die Analyse zum Vergleich so durchführen und meine strengen statistischen Ansichten zu Weihnachten etwas auflockern. Für die erste Clusterlösung werden die Antwortkategorien also als metrisch angesehen.
Streng genommen sollten wir aber beachten, dass die Fragen nur vier Kategorien (bzw. fünf, wenn die neutrale Kategorie mitbeachtet wird) haben und wir auch keine standardisierte Likert-Skala für alle Fragen haben, die die Betrachtung als metrische Variablen noch eher rechtfertigen würde. Dazu kommt, dass die ordinale Struktur in den Antworten teilweise nicht so offensichtlich ist. Für die zweite Clusterlösung werden die Antworten als nominalskaliert behandelt.
Es gibt verschiedene Algorithmen zur Bestimmung der optimalen Anzahl an Gruppen bei der Clusteranalyse. Da die Ergebnisse mit denen des Summenscores verglichen werden sollen, wird die Anzahl an Clustern von Vornherein auf drei festgesetzt, damit sie der Anzahl an laut Summenscores vorkommenden Weihnachtstypen entspricht. Als Clusteralgorithmus wird für beide Ansätze „partitioning around medoids“ (PAM) aus dem cluster-Paket verwendet.
Wir nehmen’s leicht: Numerische Antwortkategorien
Nun möchte ich damit beginnen, die erste Lösung vorzustellen, bei der die Antwortkategorien als numerisch angesehen werden. Die Antwortkategorien werden mit den Werten -2 bis 2 codiert, wobei der Wert 0 bei der Kategorie „Keine der Optionen trifft auf mich zu“ oder bei fehlenden Werten vergeben wird und ein höherer Werte eine größere Begeisterung für Weihnachten anzeigt.
Die Ergebnisse zu diesem Clusteransatz mit euklidischen Distanzen, drei Clustern und PAM-Algorithmus werden im Objekt fit_num gespeichert.
fit_num <- pam(x = df_num, k = 3, metric = "euclidean",
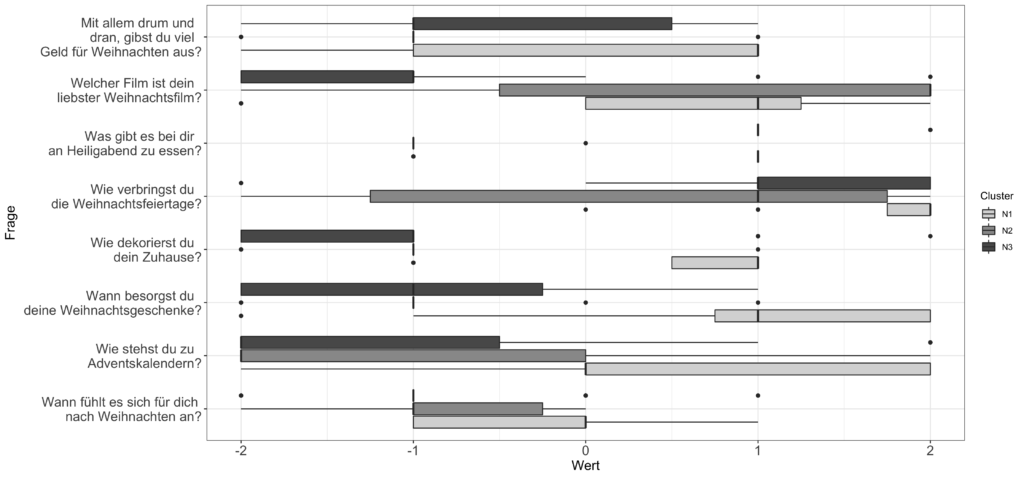
diss = FALSE, stand = TRUE)Die drei Cluster sind so verteilt, dass gut die Hälfte der Befragten dem Cluster 3 zugeordnet wird und den anderen beiden etwa gleich viele Befragte. Um die Cluster näher definieren zu können, wird die Verteilung der Fragen getrennt nach Cluster betrachtet.
Tendenziell lässt sich feststellen, dass Befragte in Cluster 3 eher weniger Begeisterung für Weihnachten aufbringen, Befragte in Cluster 1 dafür überdurchschnittlich viel. Wenn es aber um die finanziellen Ausgaben für Weihnachten geht oder die Gestaltung der Weihnachtsfeiertage, dann äußern sich die Befragten in den Clustern recht ähnlich.
Um genau zu sein: Kategoriale Antwortkategorien
Mit meinem statistischen Gewissen kann ich nicht vereinbaren, nur die bisherige Lösung zu präsentieren. Ich möchte mir zusätzlich anschauen, welches Ergebnis ich erhalte, wenn die Antwortkategorien als nominalskaliert definiert sind. Damit wird zwar auch etwas Varianz durch die eigentlich ordinale Definition verloren, da diese jedoch nur schwach ausgeprägt war, ist dieser Ansatz der genaueste.
Zunächst werden Gower-Distanzen mit der daisy()-Funktion berechnet, welche dann im PAM-Algorithmus verwendet werden.
cat_dist <- daisy(df_cat, metric = "gower")
fit_cat <- pam(x = cat_dist, k = 3, metric = "gower",
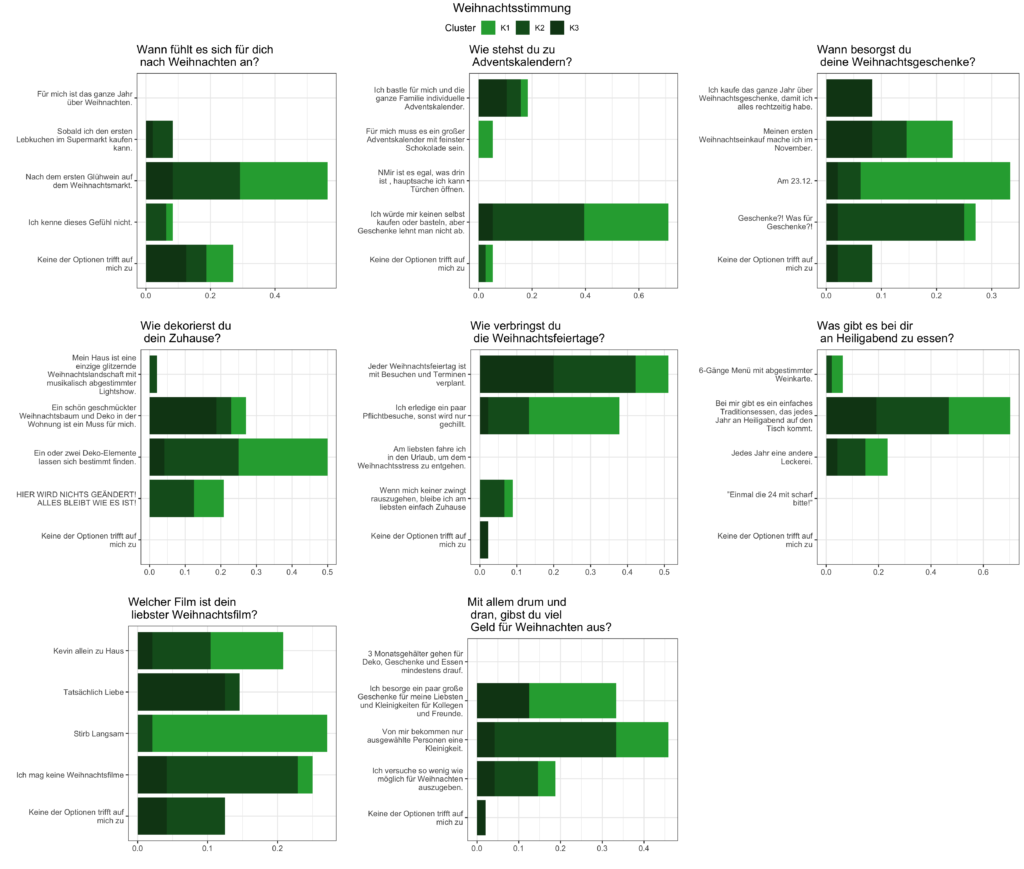
diss = TRUE, stand = FALSE)Die Verteilung der Cluster ist hier etwas einheitlicher. Das größte Cluster (Nummer 2) enthält knapp 40% der Befragten, das kleinste (Nummer 1) etwa 23%.
Für diese Clusterlösung wird graphisch die Verteilung der Antwortkategorien nach Cluster dargestellt. Zwar zeigt sich nicht, dass bestimmte Antwortkategorien nur von Befragten eines Clusters gegeben werden, es zeigt sich aber eine Tendenz. Antworten, die eine größere Begeisterung für Weihnachten darstellen, wurden eher von Befragten aus dem Cluster 3 gegeben. Befragte aus Cluster 1 und 2 antworten im Wesentlichen neutral.
(Zwar wird die Verteilung der einzelnen Fragen in diesem Post nicht besprochen, Interessierte können jedoch die Gesamtverteilung anhand der untenstehenden Grafik ablesen.)
Clusteranalyse im Vergleich zum Summenscore
Die beiden Lösungen der Clusteranalyse teilen die Befragten nicht eindeutig in Weihnachtstypen ein, was bereits anzunehmen war. Ich bin sogar ein bisschen erstaunt, dass sich bei der ersten Clusteranalyse die Wertebereiche und bei der zweiten Clusteranalyse die Antwortkategorien doch recht klar zwischen den Clustern unterscheiden. Von anderen Clusteranalysen kenne ich weit weniger eindeutige Ergebnisse.
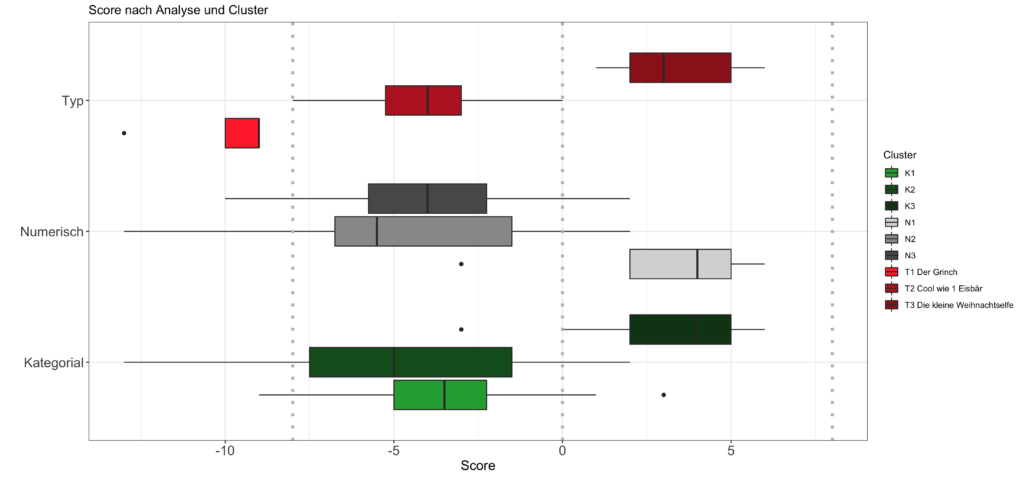
Nun möchte ich aber noch sehen, wie sich die Clustereinteilung in Bezug auf den Summenscore verhält. Überlappen die Boxen pro Analyse nicht, dann spricht das dafür, dass die Clusteranalyse keine deutlich anderen Ergebnisse hervorbringt als die Einteilung anhand des Summenscores. Dann kann ich auch endlich Frieden mit unserer Einteilung der Weihnachtstypen finden.
Als Referenz ist im folgenden Boxplot in Rot die ursprüngliche Einteilung des Weihnachtstyps anhand des Summenscores dargestellt. Die vertikalen Linien zeigen unsere selbst definierte Eingrenzung des möglichen Wertebereichs in vier gleich große Gruppen. Per Definition befinden sich die oberen Boxen also innerhalb der grauen Linien und überlappen nicht.
Bei den beiden Clusteranalysen zeigen sich bei der Einteilung der Gruppen im Hinblick auf die Scores recht ähnliche Werte (wenn man Cluster K3 und N1 vergleicht). Es fällt außerdem auf, dass Cluster T3 bei „Typ“ ziemlich exakt dem Cluster N1 bei der Analyse mit numerischen Werten und Nummer T3 bei der Analyse mit kategorialen Werten entspricht. Die extremen Weihnachtsfans, bzw. die kleinen Weihnachtselfen, wie wir sie nennen, werden also von den drei Ansätzen gleich identifiziert.
Während aber bei unserer Typeinteilung Cluster T1 und T2 notwendigerweise nicht überlappen, können bei den beiden Clusteranalysen die Cluster nicht so deutlich unterschieden werden. Dies deutet darauf hin, dass die Befragten eben nicht bei allen Aspekten Weihnachtsfreaks sind, sondern nur in vereinzelten Bereichen. Positive Werte bei einigen und negative Werte bei anderen Fragen führen dann dazu, dass sich die Werte ausgleichen und der Score im neutralen Bereich liegt.
Das Fazit des Vergleichs
Ich gebe zu, im Endeffekt hat sich die Einteilung durch den Summenscore nicht deutlich von der Einteilung durch die Clusteranalyse unterschieden. Alle drei Ansätzen identifizieren eine recht separierte Gruppe von Weihnachtsfreaks.
Bei den anderen Befragten zeigt sich aber, dass sie in manchen Aspekten unserer Ansicht von Weihnachtsbegeisterung entsprechen, in anderen Aspekten jedoch eher untere Antwortkategorien wählen, die für weniger Enthusiasmus gegenüber Weihnachten sprechen. Dies lässt sich jedoch nicht erkennen, wenn nur der Summenscore über die Kategorien gebildet wird. Die Clusteranalyse kann hier also helfen eine konkreteres Bild über die Befragten zu bekommen.
Trotzdem bin ich froh, dass mich Anne-Marie dazu überreden konnte, den Weihnachtstyp direkt bestimmen zu lassen. Da alle gleich nach Beantwortung der Fragen ein Resultat mit dem entsprechenden Weihnachtstyp erhalten haben, hatten wir im Büro viel Spaß und interessante Diskussionen zur Einstellung zu Weihnachten.
Wir möchten diesen Blogartikel auch dazu nutzen, um allen Blogbesuchern und Kunden frohe Weihnachten und einen guten Start ins Jahr 2020 zu wünschen.
Wenn du mehr über die Clusteranalyse oder andere statistische Verfahren erfahren möchtest, dann wende dich gerne an uns.
Über den Autor
ABOUT US
STATWORX
is a consulting company for data science, statistics, machine learning and artificial intelligence located in Frankfurt, Zurich and Vienna. Sign up for our NEWSLETTER and receive reads and treats from the world of data science and AI. If you have questions or suggestions, please write us an e-mail addressed to blog(at)statworx.com.